在当今数字化浪潮席卷全球的时代,数据已成为驱动社会进步与商业创新的核心引擎。从社交媒体上的互动信息,到物联网设备产生的实时流,再到企业运营中积累的交易记录,海量数据正以前所未有的速度与规模持续生成。拥有数据本身并不直接等同于价值,关键在于如何对其进行高效、智能的处理与深度挖掘,从而将原始数据转化为可指导行动的智慧。
一、海量数据处理:应对巨量、多样与高速的挑战
海量数据处理的首要挑战在于其“海量”特性——数据体量(Volume)巨大,通常达到TB、PB乃至EB级别。这要求处理系统必须具备强大的存储与计算能力。传统单机数据库或处理工具往往难以胜任,分布式计算框架如Hadoop、Spark以及云原生数据仓库(如Snowflake、BigQuery)应运而生,它们通过将计算任务拆分到成百上千个节点上并行执行,有效解决了规模瓶颈。
数据多样性(Variety)日益显著。结构化数据(如数据库表格)仅占冰山一角,半结构化(如JSON、XML日志)和非结构化数据(如文本、图像、音视频)占比激增。数据处理流程必须能够兼容多种格式,并具备提取、清洗与整合多源异构数据的能力,例如利用NoSQL数据库(如MongoDB)存储灵活模式的数据,或使用数据湖(Data Lake)架构集中存储原始数据。
数据生成与处理的速度(Velocity)要求极高。在金融风控、实时推荐等场景中,数据价值随时间快速衰减,批处理模式(如每日ETL作业)已无法满足需求。流式处理技术(如Apache Kafka、Flink)实现了数据的实时摄入、处理与分析,支持毫秒级响应,让业务洞察与决策能够“与数据流动同步”。
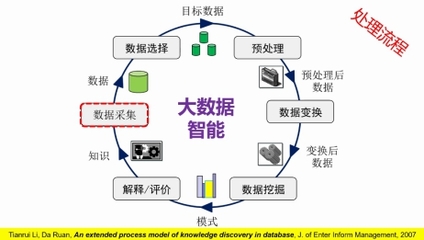
二、从数据处理到数据挖掘:发现隐藏的价值模式
数据处理为数据挖掘奠定了坚实的基础。数据挖掘旨在通过算法从海量数据中发现潜在的模式、关联与知识,其核心环节包括:
- 数据预处理:这是挖掘成功的关键。原始数据常含有噪声、缺失值与不一致性。通过数据清洗、集成、变换与规约(如特征选择、降维),可以提升数据质量,为后续分析提供“干净”的输入。
- 模式发现:运用机器学习、统计学等方法进行深入探索。例如,通过分类算法(如决策树、神经网络)预测客户行为;通过聚类分析(如K-means)对用户进行细分;通过关联规则挖掘(如Apriori算法)发现“啤酒与尿布”式的商品组合规律;通过时序分析预测未来趋势。
- 知识评估与呈现:将挖掘出的模式转化为易于理解的见解。这离不开数据可视化(如交互式仪表盘)与清晰的业务解读,确保分析结果能够有效支持战略决策与运营优化。
三、技术融合与最佳实践
处理与挖掘海量数据是一个系统工程,需要多项技术的协同:
- 云计算与弹性架构:云平台提供了按需伸缩的计算、存储资源,使企业无需预先巨额投资硬件,即可灵活应对数据量的波动。
- 人工智能的深化应用:深度学习等AI技术在图像识别、自然语言处理等非结构化数据挖掘中表现卓越,极大地扩展了数据价值的边界。
- 数据治理与安全:在利用数据的必须建立完善的数据质量管理、元数据管理、隐私保护(如差分隐私、联邦学习)与安全合规体系,确保数据的可信、可用与合法使用。
四、展望:走向智能化与价值闭环
海量数据的处理与挖掘将更加自动化与智能化。AutoML技术正尝试降低建模门槛;增强分析(Augmented Analytics)将AI融入分析全流程,主动提示洞察。最终目标是构建从数据采集、处理、挖掘到决策行动、效果反馈的完整价值闭环,让数据真正成为流淌在组织血脉中的“智慧血液”,持续赋能精准营销、智慧城市、科学研究和产业升级等方方面面。
总而言之,面对海量数据,我们既要通过分布式、实时化、云原生的技术栈构建坚固高效的“数据处理管道”,也要借助先进的挖掘算法与AI工具充当敏锐的“价值探测仪”。唯有将二者紧密结合,才能在数据的海洋中精准导航,发掘出驱动未来发展的无尽宝藏。